I Ran 8 Queries Across ChatGPT, Perplexity, Claude, Gemini, and AI Overviews to See What Content Gets Cited.
Everyone's talking about optimizing for "AI search." But there is no single AI search.
ChatGPT, Perplexity, Claude, Gemini, and AI Overviews each decide differently whether to search, what to read, and what to cite. Some queries don't even trigger a search: the model answers from training data, but here you are betting on random content.
So I ran a little experiment to answer a simple question: when you ask each platform a query with a specific intent (commercial, advisory, comparison, navigational) what's the search logic, and what content types get cited?
I ran 8 queries spanning commercial, advisory, comparison, data, definitional, and navigational intent across all 5 platforms. Same queries, same day, fresh conversations.
But I wanted to entertain a thought, and the patterns pointed to something most content strategies are missing entirely: the platform you're targeting determines whether your content type can even be cited.
What you'll learn today:
- Which content intent types trigger search on which platforms (and which get ignored completely)
- The one content strategy that worked across all 5 platforms
- A step-by-step method to run this audit for your own queries and build a content-to-platform map
The Setup
The 8 queries I picked:
- "best CRM for startups" commercial broad
- "Asana vs Monday vs ClickUp" commercial comparison
- "Asana pricing 2026" commercial brand
- "best tools to reduce churn in SaaS" commercial niche
- "how to reduce churn in SaaS" advisory/strategy
- "SaaS churn benchmarks 2026" data/research
- "what is a CRM" definitional
- "Stripe billing documentation" navigational
Each query ran in a fresh conversation on every platform's web UI. No conversation history, no priming. I captured every source panel. Same queries, same day.
The platforms: ChatGPT, Perplexity, Claude, Gemini, and Google AI Overviews.
LLMs Don't Agree on Whether to Search
This was the biggest surprise. I expected different sources across platforms. I didn't expect them to make fundamentally different decisions about whether to search at all.
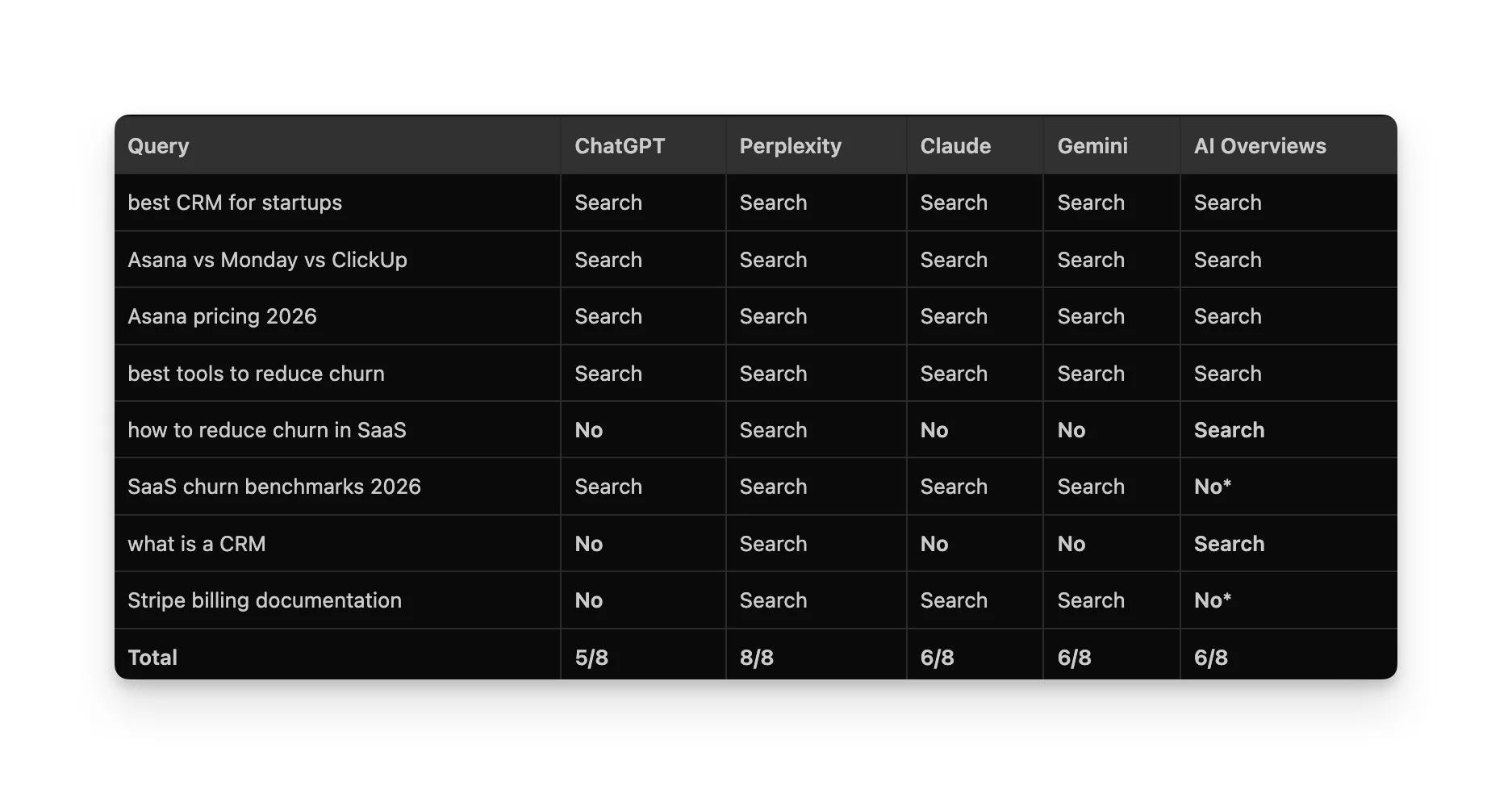
AI Overviews showed a featured snippet or pure organic results instead.
What I'd loosely characterize as each platform's approach:
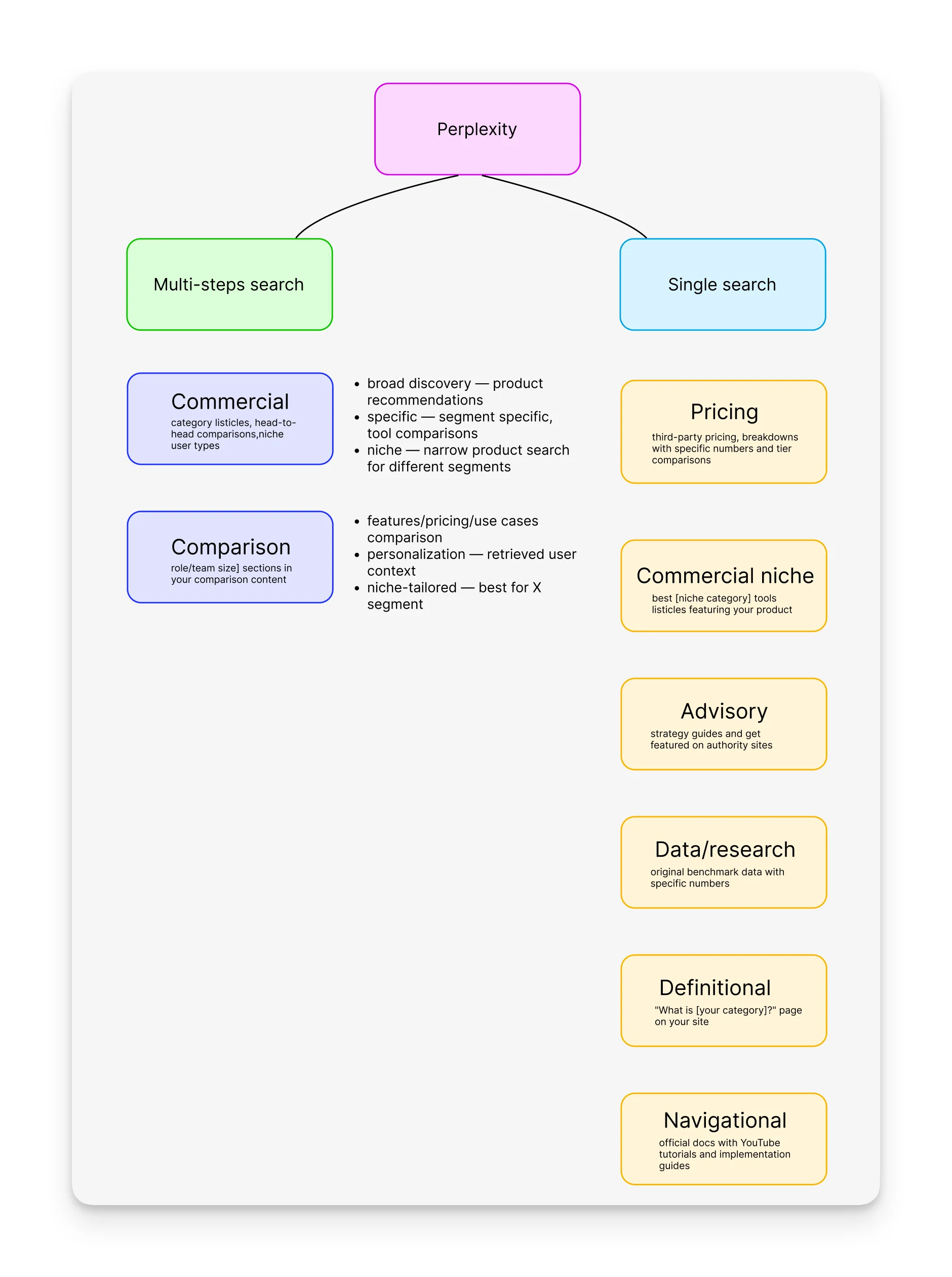
Perplexity always searches (8/8). It grounds every single answer with web sources, no matter what.
Claude and Gemini skip definitional and advisory queries (6/8). They seem to reason, "I'm confident enough to answer this from what I know."
AI Overviews skips navigational and precise data queries (6/8). Google already has direct links and featured snippets for those.
ChatGPT is the most selective (5/8). It skips advisory, definitional, and navigational queries. It only searches when it thinks the information might be outdated.
Why pay attention to this?
If a platform doesn't search for your query type, your content cannot be cited.
"How to reduce churn in SaaS" strategy content? Invisible on ChatGPT, Claude, and Gemini. They answer from training data. But it absolutely gets cited on Perplexity and AI Overviews.
A Note on API vs. Web UI
Before comparing platforms, I tried to understand how ChatGPT's search actually works internally. I went through three approaches, and honestly, it's worth sharing because it shaped how I ran the rest of the experiment.
1. Browser DevTools ❌
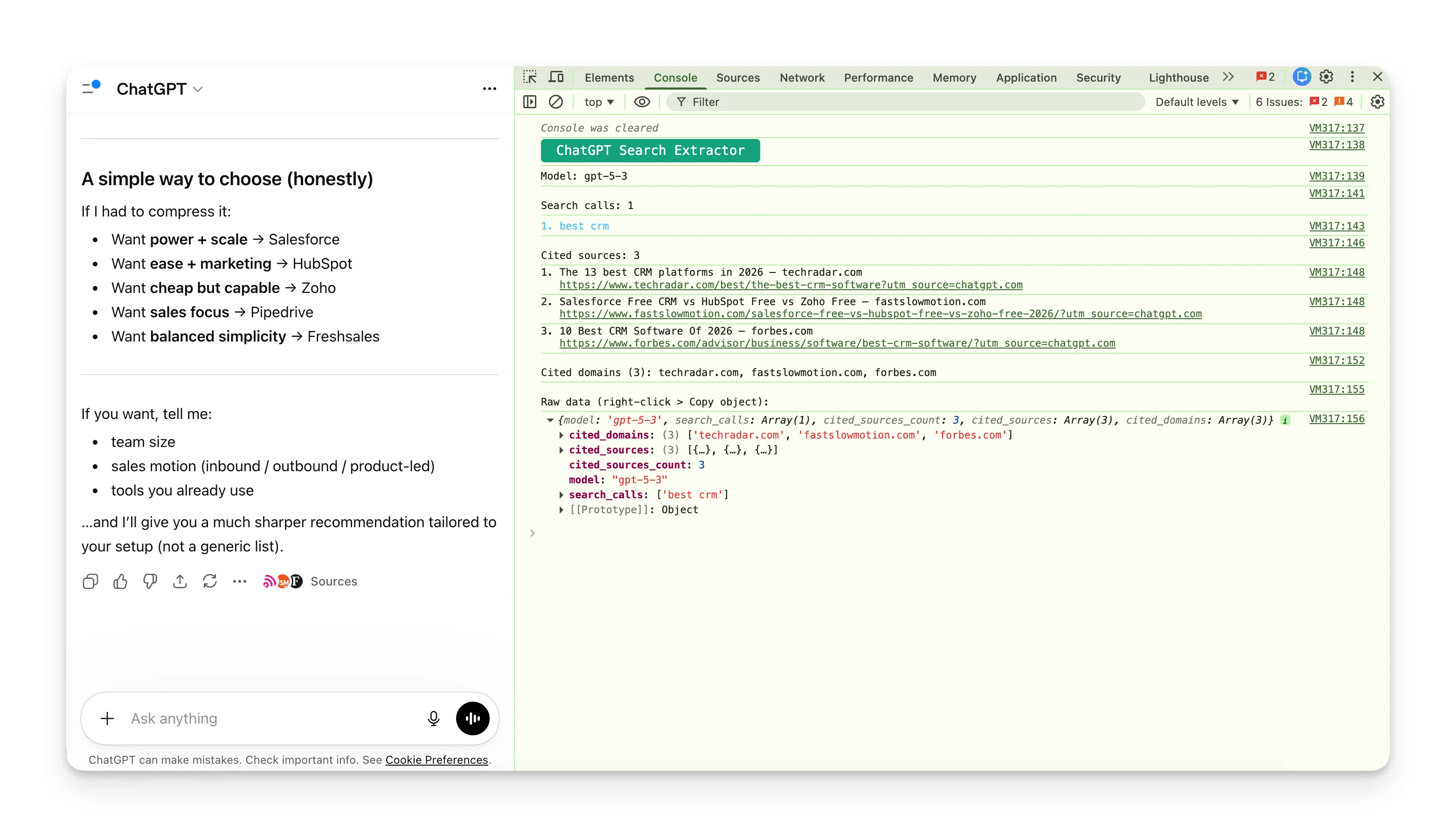
Made a console script to intercept ChatGPT's internal API stream and extract the search queries it fires. It mostly failed: the script couldn't reliably capture the data, and what it did catch showed a single simple query ("best crm") with only 3 cited sources.
Boring, next.
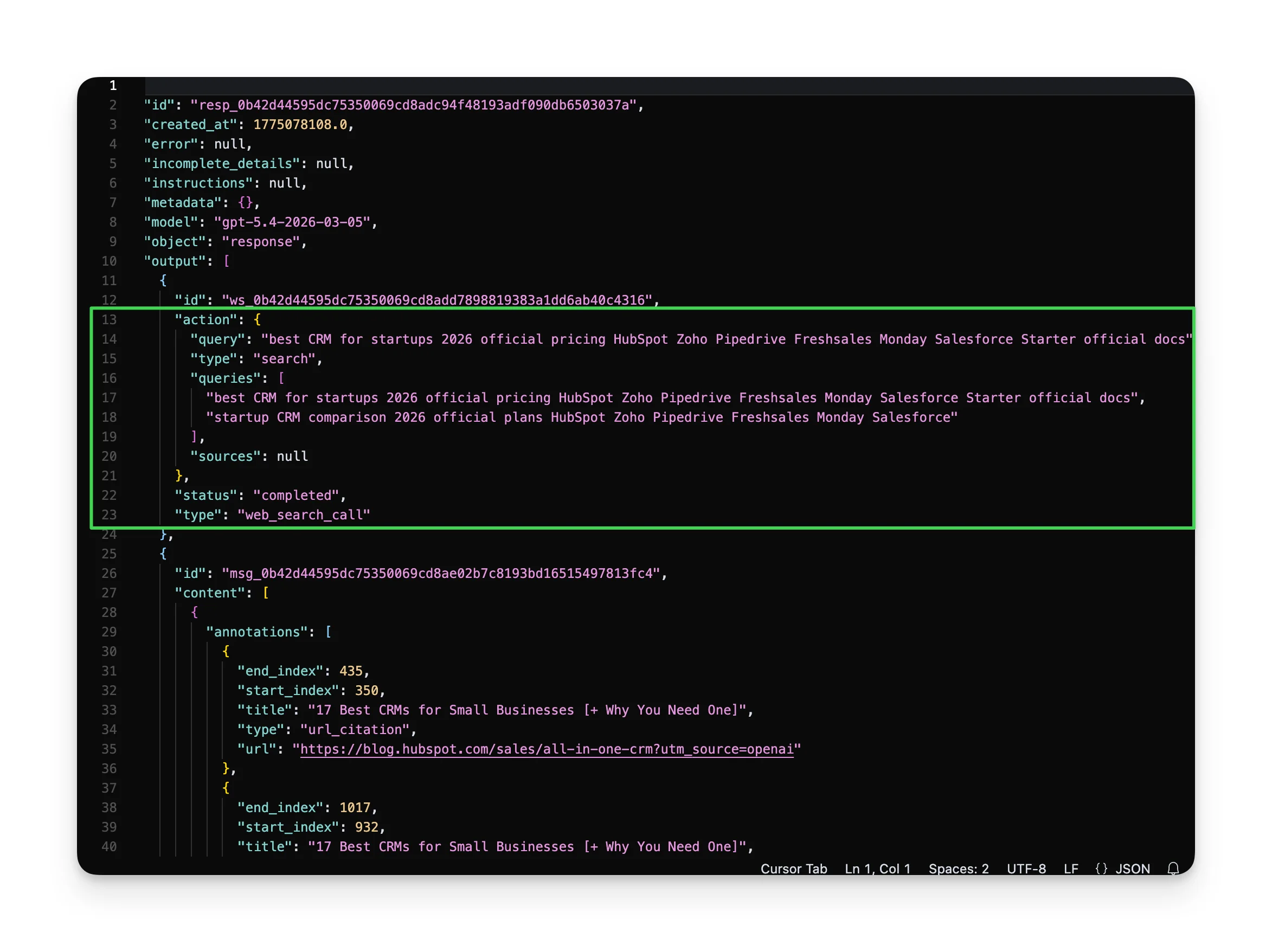
2. OpenAI API ❌
This worked better. The API exposes the sub-queries ChatGPT generates. For "best CRM for startups," the API didn't just search the phrase, it sent:
- "best CRM for startups 2026 official pricing HubSpot Zoho Pipedrive Freshsales Monday Salesforce Starter official docs"
- "startup CRM comparison 2026 official plans HubSpot Zoho Pipedrive Freshsales Monday Salesforce"
Brand names were already baked into the queries. ChatGPT didn't search to discover which CRMs existed. It searched to validate and update. BUT the API only returned 2 cited sources for that query.
3. Web UI 🎉
This is what I settled on. The web UI returned 25-30+ sources, and more importantly, it's what users usually opt for. I didn't find it productive to base content strategy on API behavior, since it doesn't match the product people use.
How Each Platform Searches (IF It Does.)
ChatGPT: Three Layers in One Answer
ChatGPT's web UI shows the most sources of any platform (25-30+ per query). But what makes it interesting is that a single response blends 3 systems:
- The model's own knowledge. In the API, we could see that ChatGPT's search queries already contained brand names (HubSpot, Salesforce, Zoho, Pipedrive) before any search happened. The web UI may work differently, but the API suggests the model already has opinions about which brands matter before it searches. So it's more of a confirmation search: validating and updating what it already knows, instead of discovering from scratch.
- Web search. Current details get pulled from live sources and are cited inline. When search triggers, the source panel is massive.
- UI enrichment. When the model mentions a well-known product, ChatGPT shows a knowledge card alongside the answer. These cards have their own sources: official websites, app store listings, LinkedIn company pages, review platforms (Trustpilot), developer docs, and startup directories.
This means that even on queries where ChatGPT seemingly doesn't search, brands can still get visibility through knowledge cards, but the content that feeds them is quite different from the content that feeds search results. So, there are essentially 3 different opportunities to get in.
When search triggers, the source types skew heavily toward listicles and vendor comparison content.
Search pattern:
Hard to map as its thinking process isn't visible.
Perplexity: Three-Step Progressive Research Chain
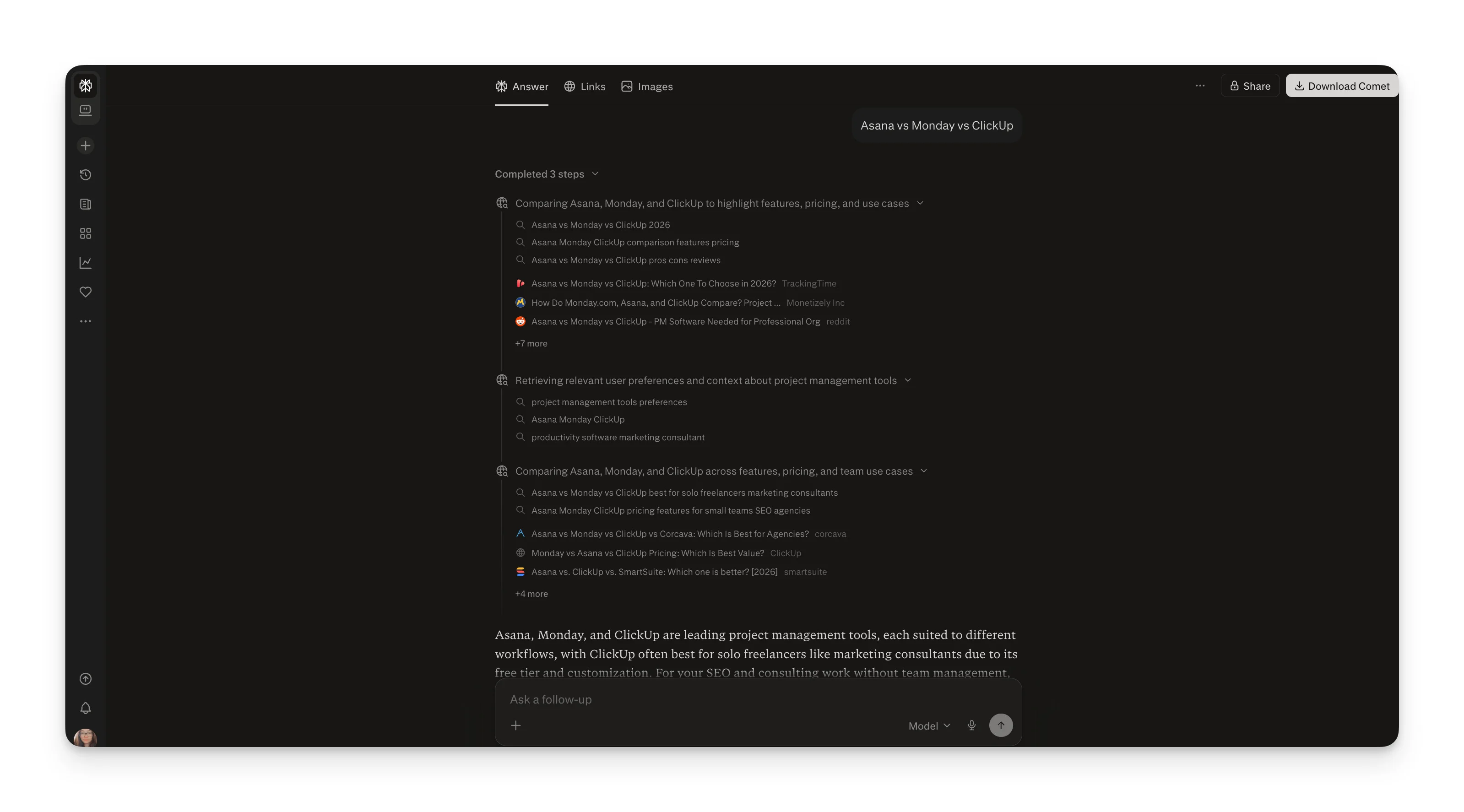
Perplexity (in Pro mode) runs a visible 3-step process:
- Broad discovery searches the query as-is
- Specific comparison narrows to top contenders
- Niche deep-dive tailors to specific use case scenarios
Search pattern:
Claude: Single Query, Transparent Reasoning
Claude runs one search with one query. Also has visible thinking, so you can see it decide:
"This is a current topic where recommendations may have changed, so I should search for up-to-date information."
"Simple factual question, no need for tools."
Its source mix looks like traditional search results. No Reddit, no YouTube, no Wikipedia. But it uniquely cited interactive tools (CostBench calculator, PM Toolkit calculator) that no other platform surfaced.
Claude's decision logic maps to "has this changed recently?" If your content is about something that evolves (pricing, tools, benchmarks), Claude will search for it. If it's stable knowledge (definitions, strategy), it won't.
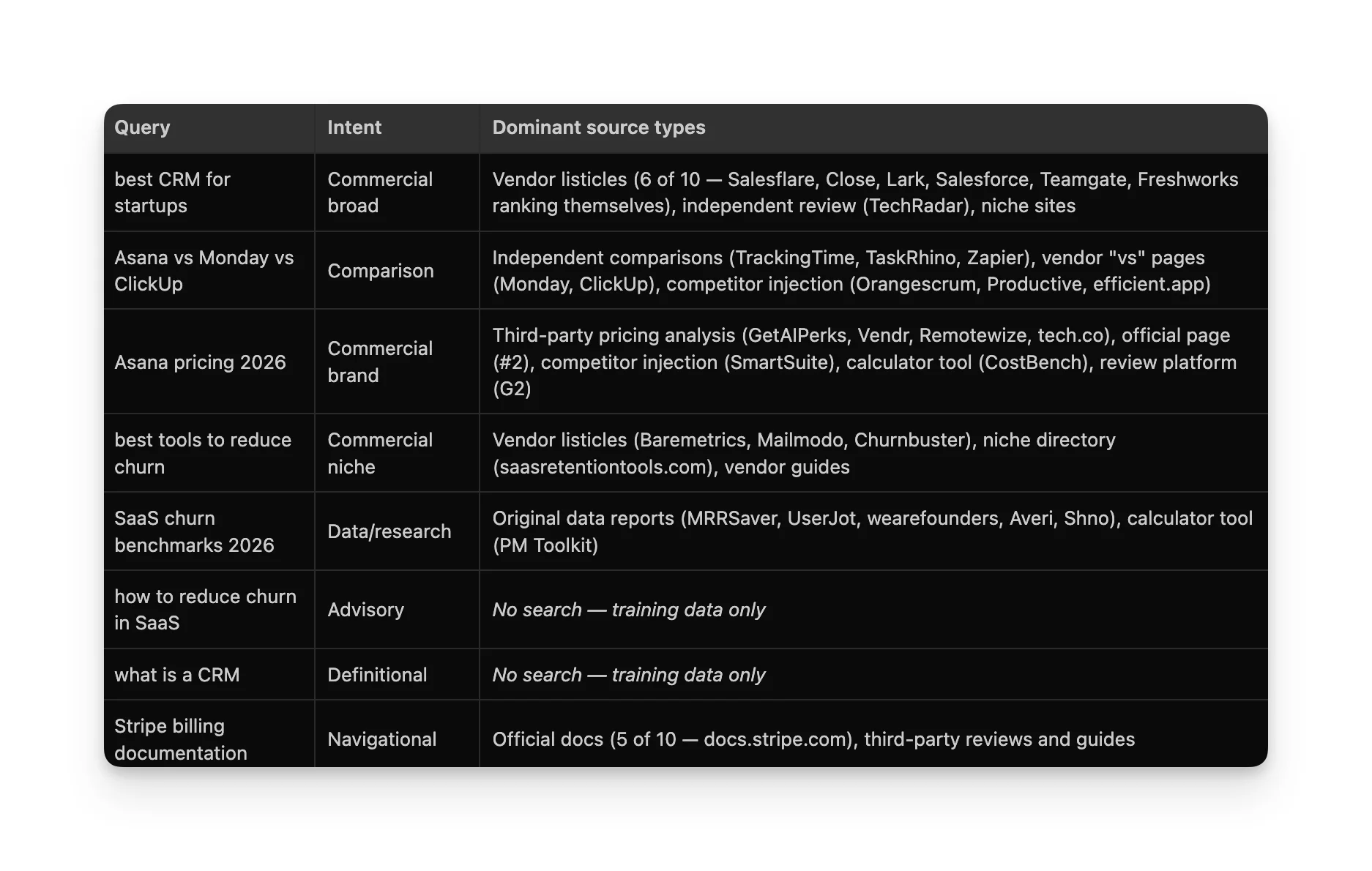
Search pattern:
Claude’s decision logic maps to “has this changed recently?” If your content is about something that evolves (pricing, tools, benchmarks), Claude will search for it. If it’s stable knowledge (definitions, strategy), it won’t.
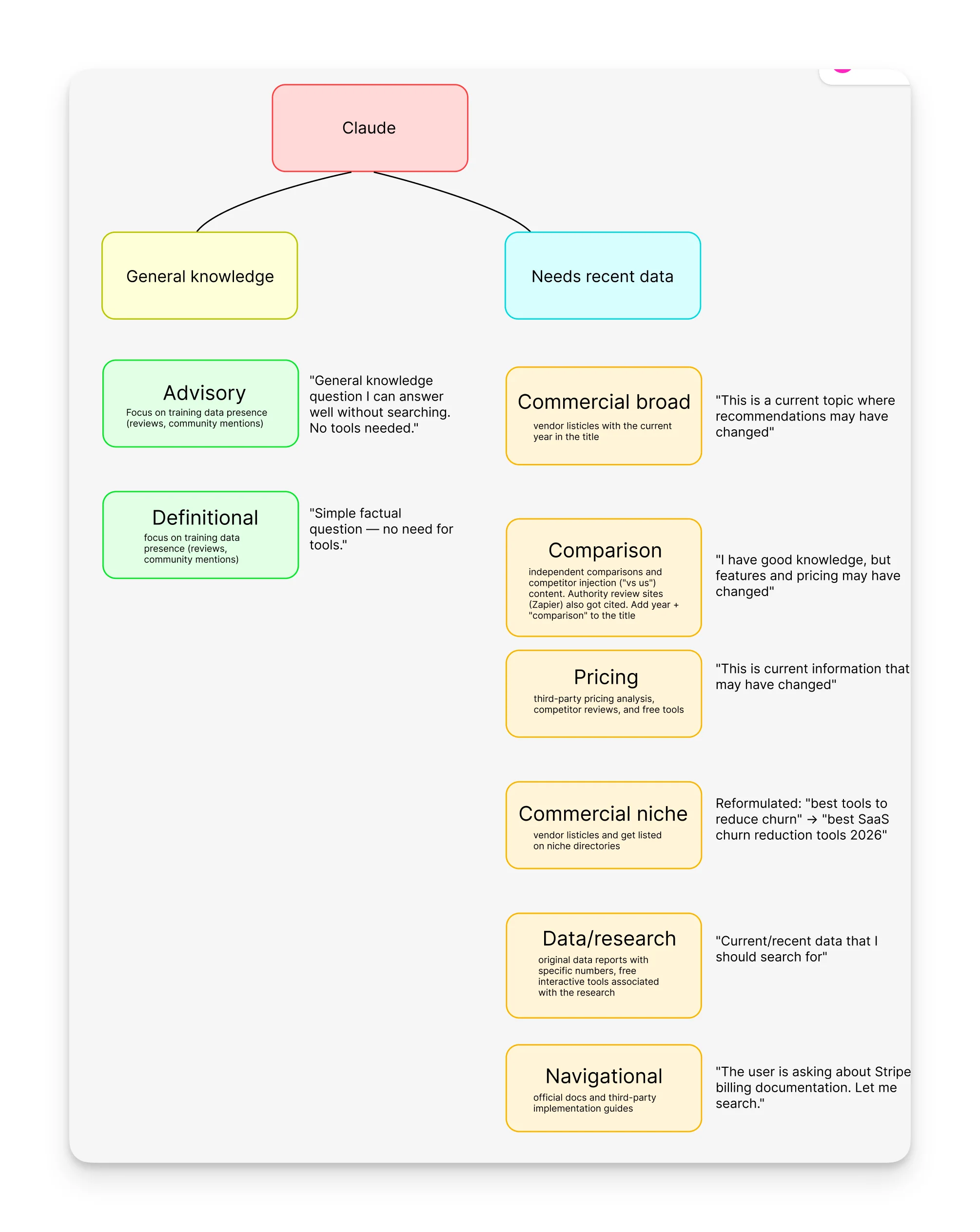
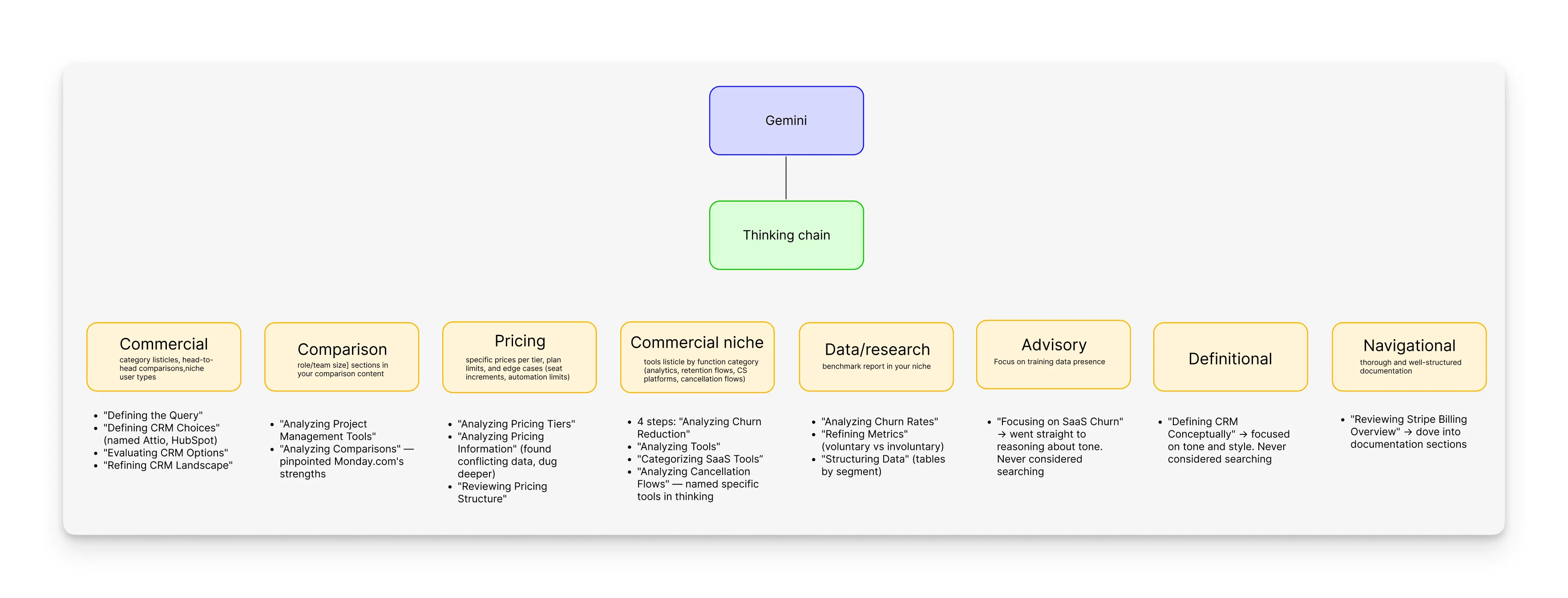
Gemini: Reasoning-First, Wildly Variable
Gemini in Pro mode gave 2 sources for "best CRM for startups" and basically answered from reasoning. But for pricing queries, it went to 20+ sources and 15+ for benchmarks.
Search pattern:
Its thinking chain is the most detailed, with 3-4 reasoning steps, naming tools, and categories before showing results.
AI Overviews: Google Search + Selective AI Synthesis
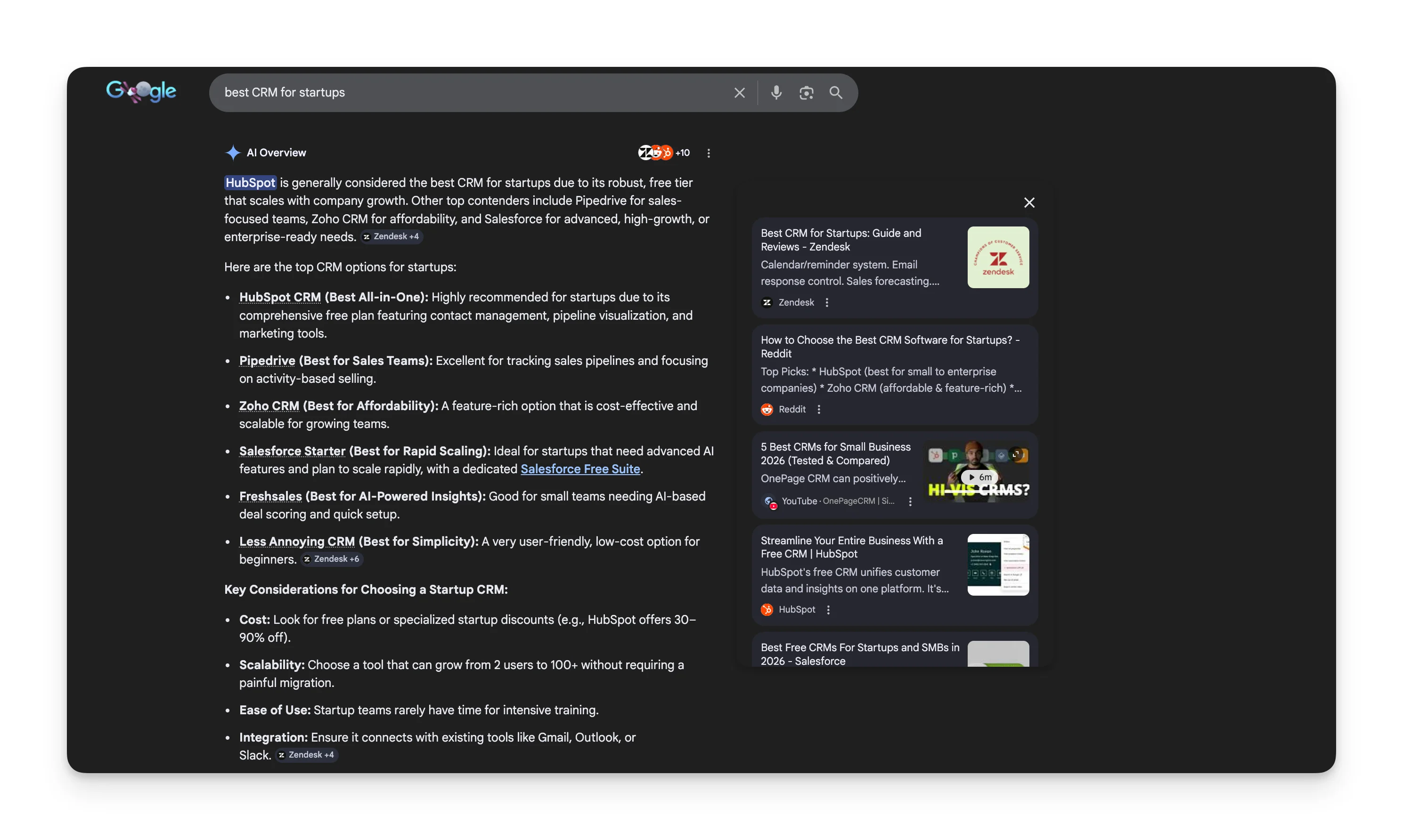
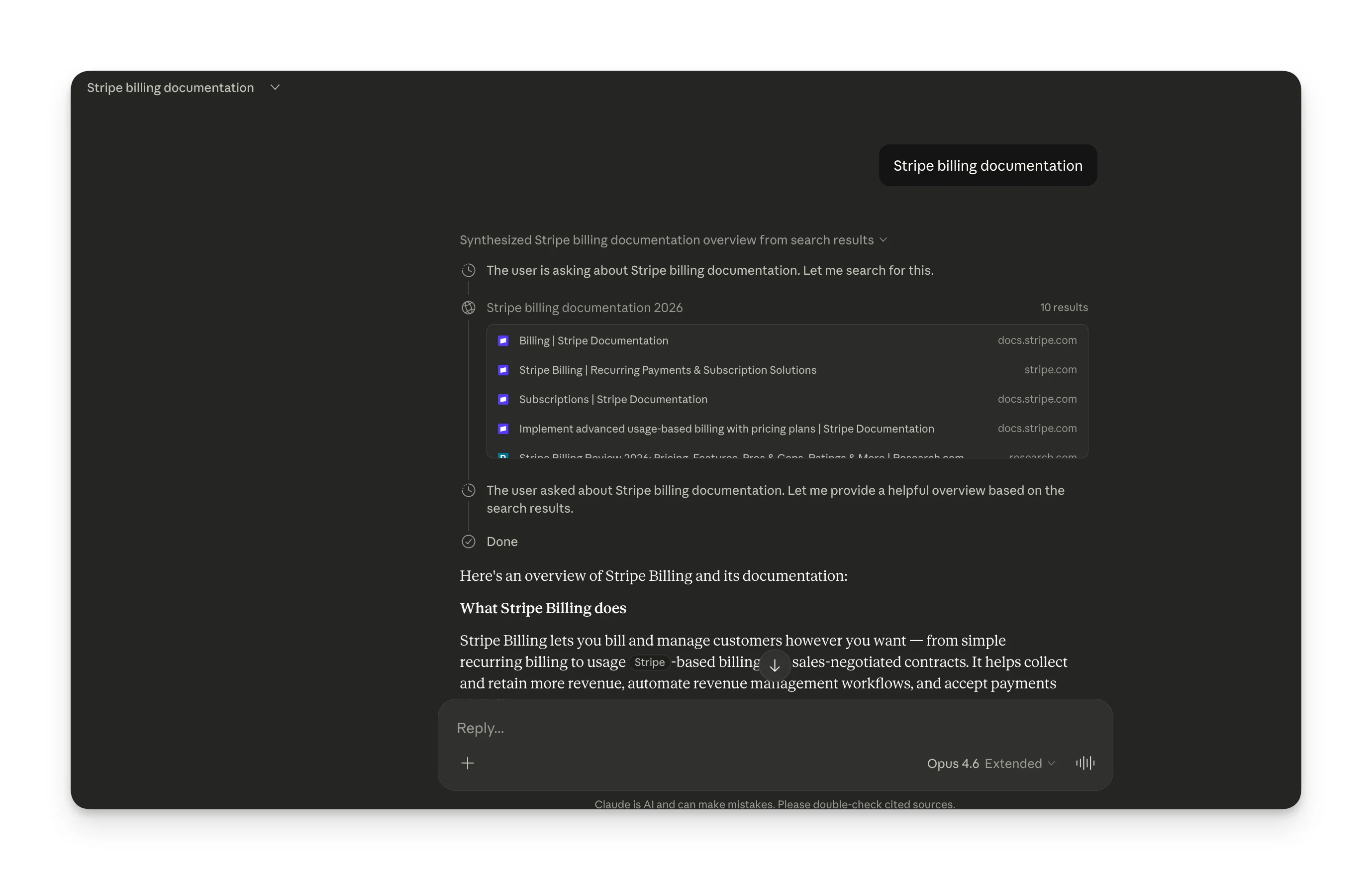
AI Overviews sits on top of Google's full search index. The question isn't whether to search, it's whether to generate an AI synthesis or let traditional results handle it. For "Stripe billing documentation" Google just showed organic links to Stripe's docs, because AI synthesis would've been worse than a direct link. For "SaaS churn benchmarks," it showed a featured snippet with the exact number. But for "what is a CRM," it generated a full AI Overview.
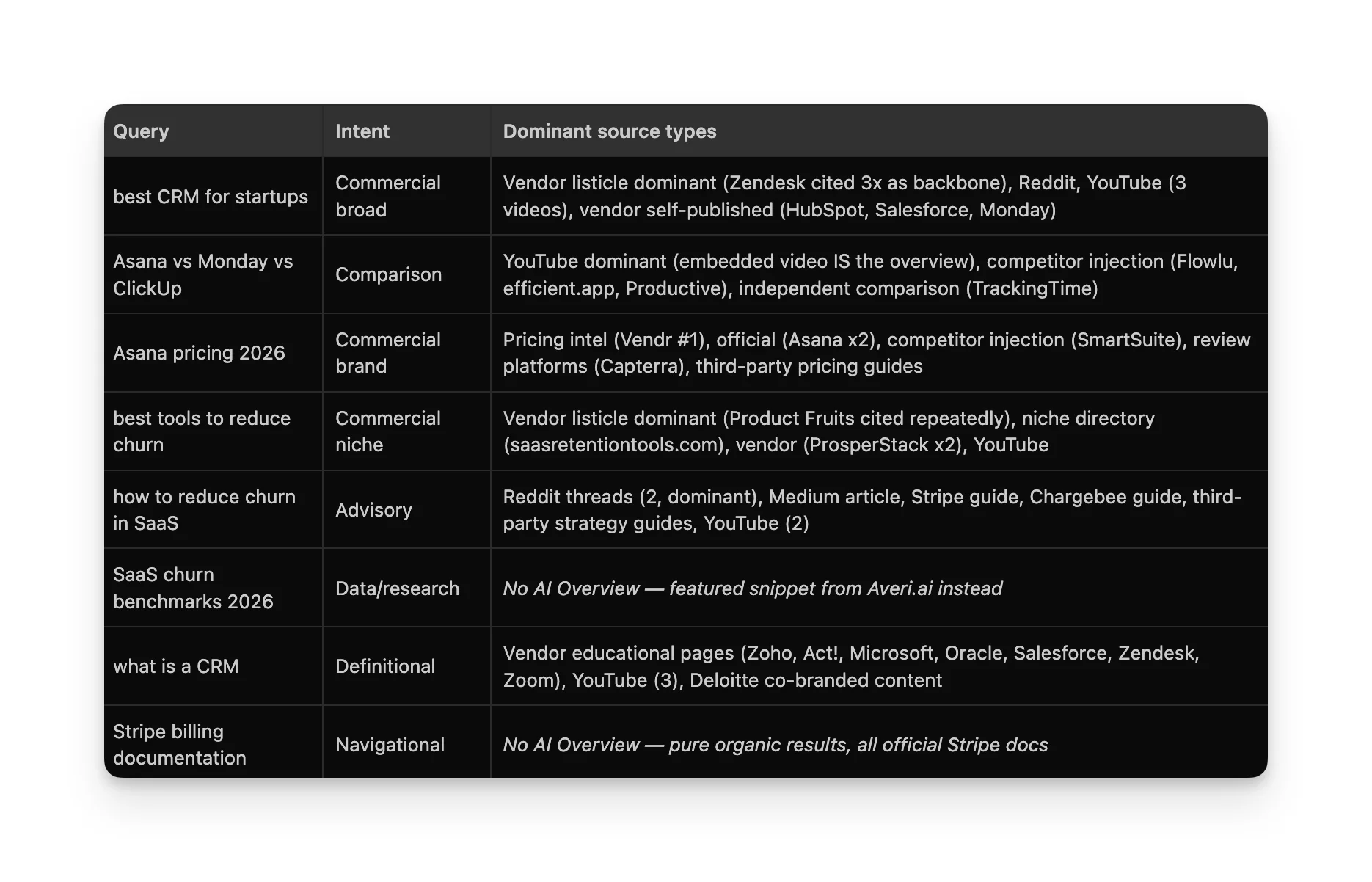
AI Overviews is the YouTube/Reddit platform. YouTube appeared in 5 out of 6 triggered queries, and for "Asana vs Monday vs ClickUp," a video was the answer, not just a source. Reddit dominated the advisory query.
Search pattern:
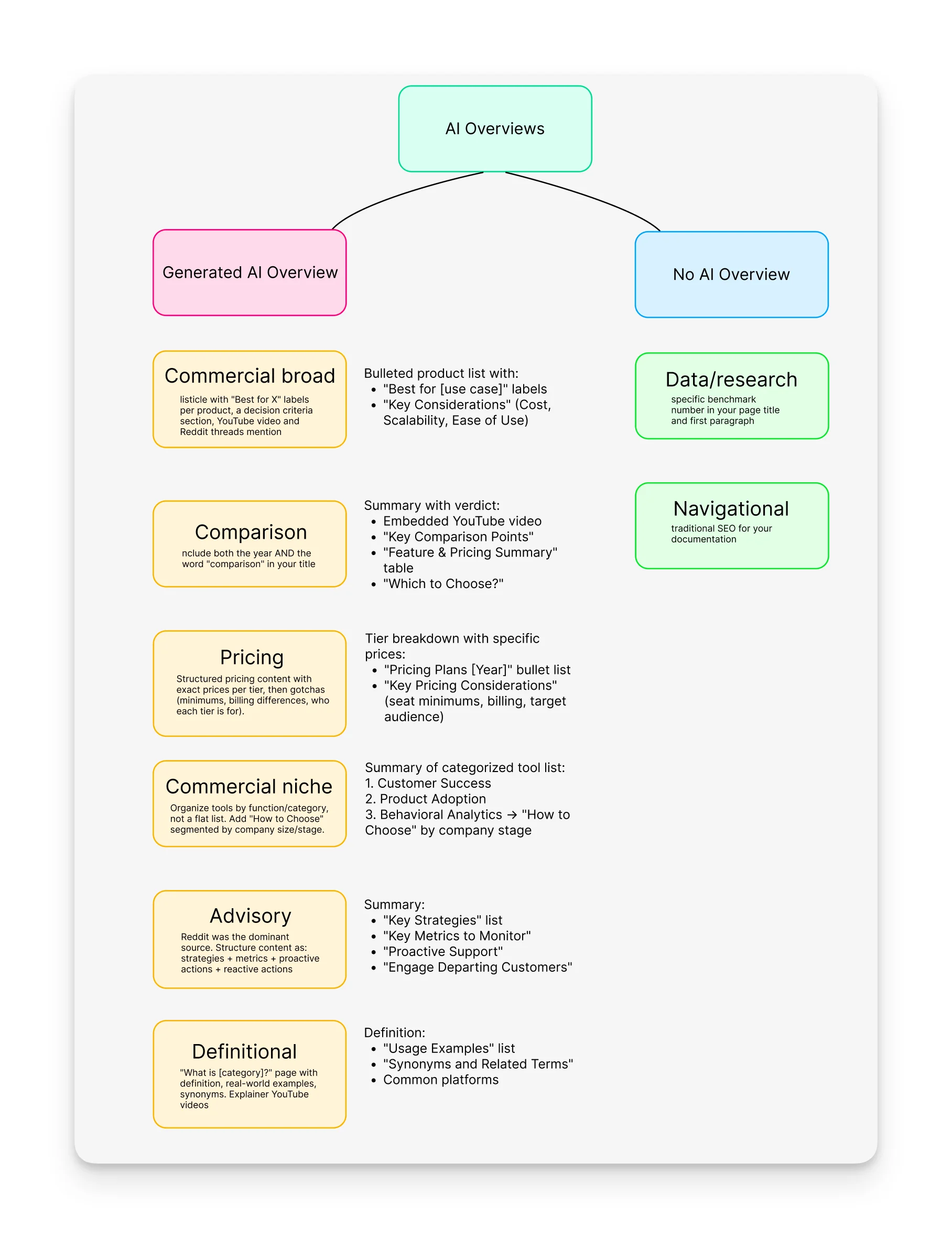
Cheatsheet
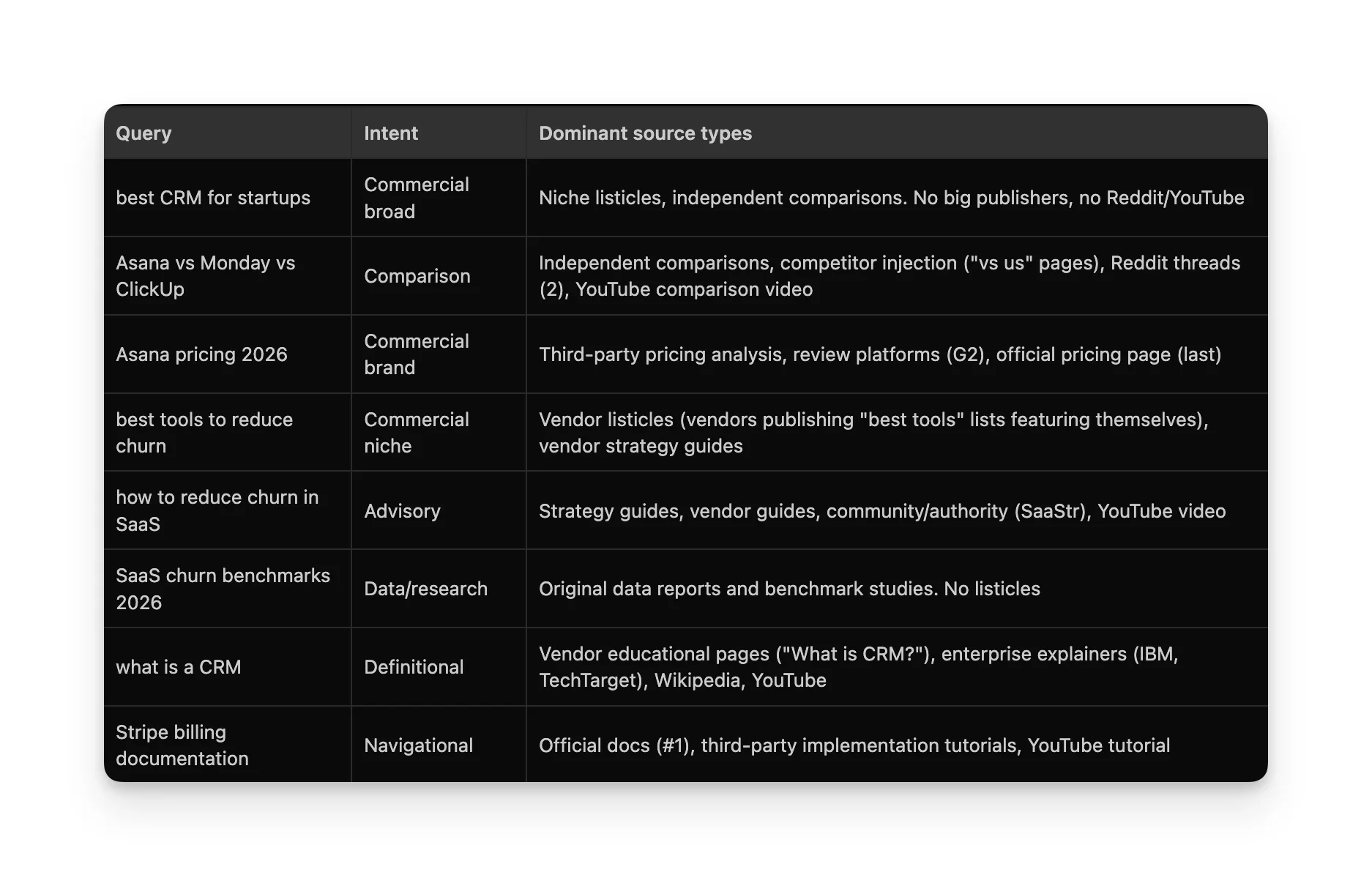
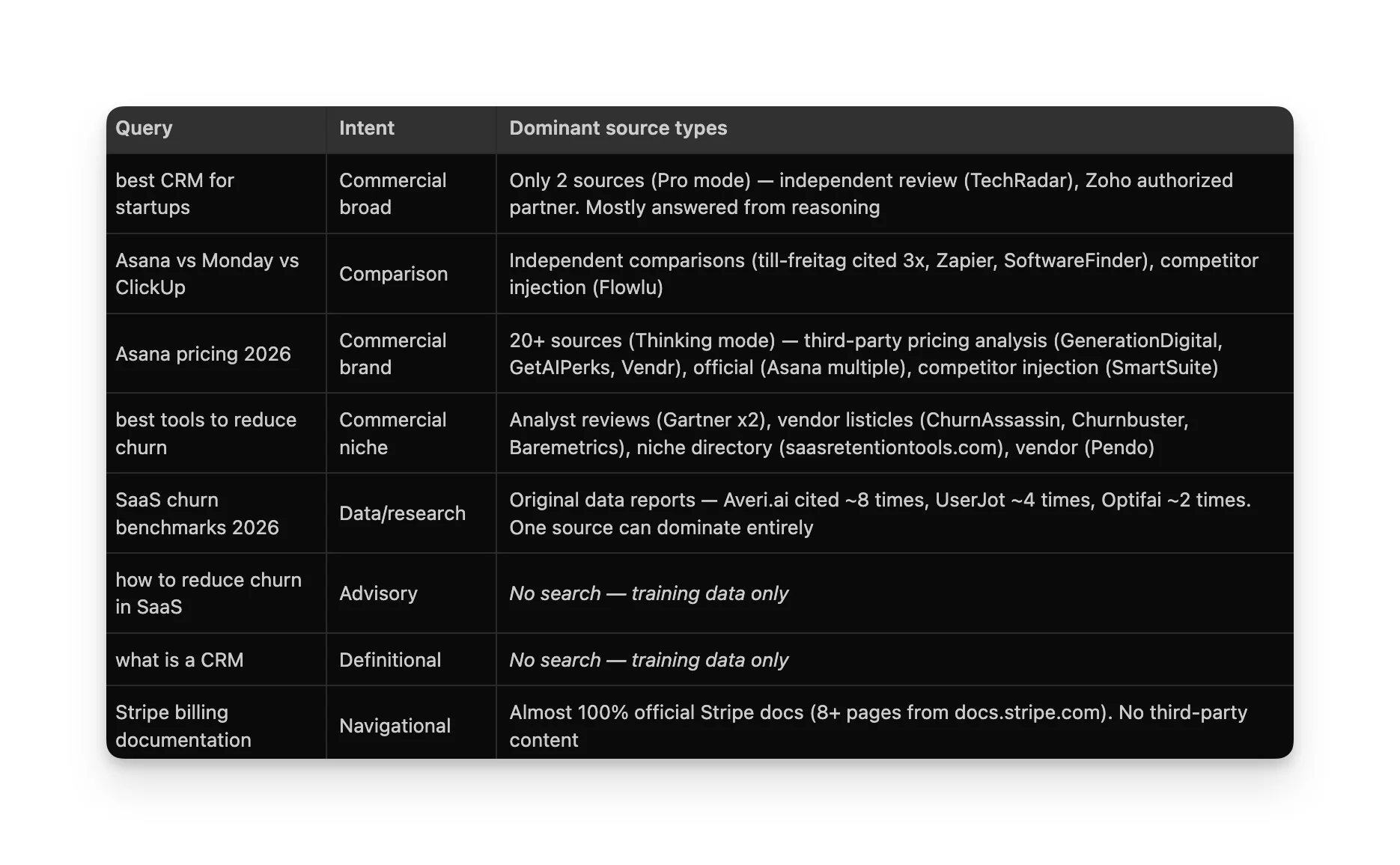
This is what the experiment boiled down to. One table based on what content type was cited, on which platform, and for which intent.
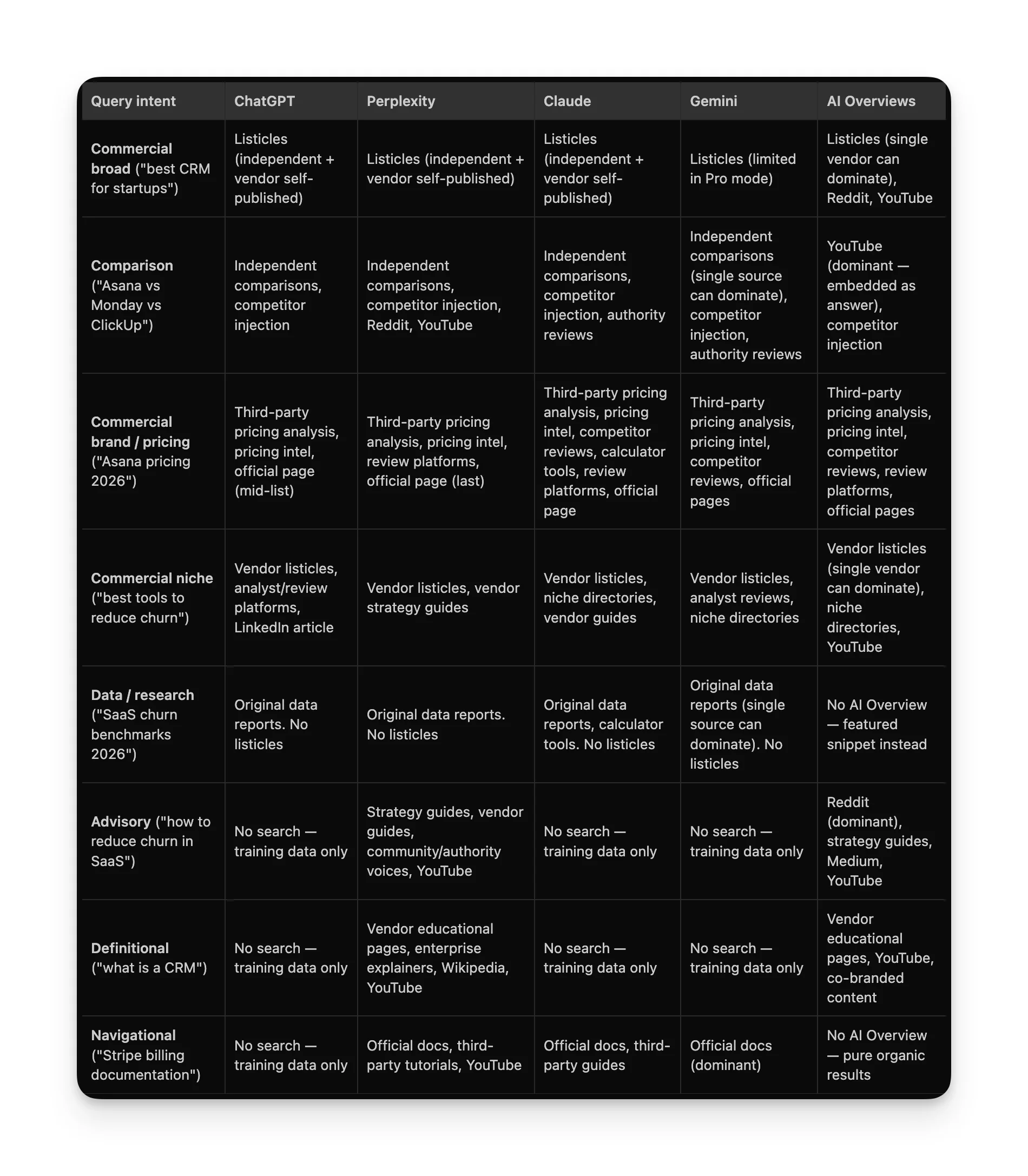
What about the training data?
For queries where search doesn't trigger, the only real strategy is broad ecosystem presence:
- Get mentioned on review platforms G2, Capterra, TrustRadius
- Get discussed in communities Reddit
- Get listed on aggregator/directory sites industry-specific directories in your niche
- Get written about not just your own content, but other people's blog posts, newsletters, roundups mentioning you
The logic: training data is a snapshot of the web. The more places you appear, the more likely you are to be in that snapshot. But we're all guessing about the lag time. If anyone has seen research on this, I'd love to hear about it.
Fun experiments like this
If you run this experiment for your own space, I'd genuinely love to see what you find. The more data points we have across different verticals and geographies, the better everyone's mental model gets.
The AI search landscape isn't one landscape. It's five, and they're all moving. The question isn't "how do I optimize for AI?", it's "which AI platforms matter for my queries, and what does each one actually reward?".
