How IBM Wins AI Search: Content Architecture Behind #1 for AI Agent
IBM currently holds three search positions most B2B companies would trade a quarter's ARR for.
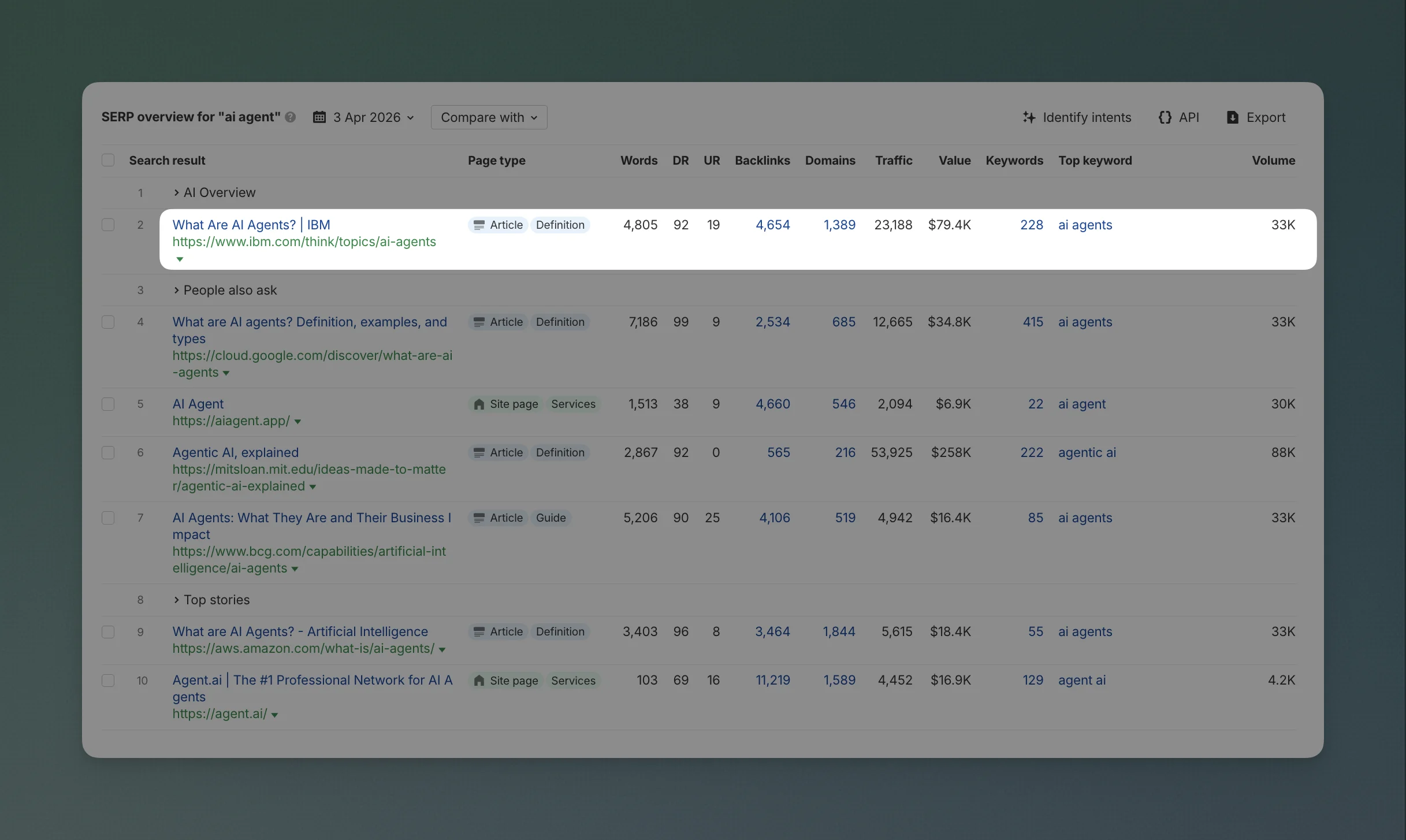
- #1 for "ai agent" bringing 23k traffic
- #1 for "what is ai" bringing 241k traffic
- #4 for "ai" - same page as for "what is ai"
Not "IBM AI."
Just "ai."
A two-letter query with global search volume in the millions and an SERP contested by every AI-native startup, foundation model lab, and cloud hyperscaler on earth.
IBM is beating all of them across hundreds of related queries.
IBM's content program is the result of a deliberate, six-year buildout run by a team led by Brian Casey. Casey also gave a conference talk that exposed most of the playbook.
This is a full teardown: the architecture, the SEO mechanics, the multi-channel flywheel that makes the whole thing compound, the operational rules that enable it to ship at scale, and the 84,000-page research subdomain he didn't mention.
The architecture
IBM's inbound content program consists of six connected assets, each built with a goal to create a connected network.
| # | Asset | Added | Scale | Primary job |
|---|---|---|---|---|
| 1 | Pillar pages + lightboard video | Year 1 | 1.64M YouTube subscribers | Dual-format coverage of head terms |
| 2 | Twice-weekly newsletter | Year 3–4 | Tens of thousands of new subs per month | Audience subscription, durable distribution |
| 3 | News-cadence podcasts | Year 3–4 | 2 shows, Friday 5am publish | Relevance signal, embedded on evergreen pages |
| 4 | Technical tutorials | Year 5 | In-house PhDs | Developer TAM |
| 5 | Topic hubs (restructuring) | Year 5–6 | Many hubs, flagship AI agent hub has ~70 pages | Topical authority + query fan-out |
| 6 | GitHub destination | Recent | Active org + READMEs | Closes the loop for technical audience |
But before we get into Casey's program, it helps to see what IBM.com looks like from the outside. I crawled their sitemaps to map the full architecture.
The sitemap today
IBM's ibm.com/sitemap.xml returns a 404. Weird. So, what I found is that IBM declares 6 separate sitemaps in their robots.txt, but only 3 of them actually work:
| Sitemap | Status | What it is |
|---|---|---|
href-sitemap-index.xml | 200 | Hreflang index, 17 locale sub-sitemaps |
IBM_Adobe_Sitemap.xml | 200 | Adobe CMS index, 20 locale sub-sitemaps |
mysupport/s/sitemap.xml | 200 | Salesforce support portal, 25 sub-sitemaps |
docs/sitemap.xml | 302 | Redirects (broken or moved) |
new-news-sitemap.xml | 404 | Dead |
think-news-news-sitemap.xml | 404 | Dead |
My hypothesis on why this is happening: I think IBM.com runs on multiple platforms simultaneously, and nobody owns the coordination layer between them. The evidence is there:
| Platform | Evidence |
|---|---|
| Adobe Experience Manager | Sitemap lives at /content/dam/adobe-cms/, AEM's default DAM path. Product page HTML uses AEM component classes. |
| Salesforce Experience Cloud | Support sitemap uses the /s/ path (Salesforce's default for community portals). Sub-sitemaps named sitemap-defect__c-1.xml use Salesforce's __c custom object naming. |
Separate system for /think/ | The hreflang sitemap XML contains a literal comment: Created with HREFLang Builder http://www.hrefbuilder.com. If /think/ were on AEM, hreflang sitemaps would come from AEM's built-in module, not a standalone third-party tool. |
| Separate app for research.ibm.com | Different subdomain, different sitemap structure, no shared CMS fingerprints with the main site. |
If this is right, a standard /sitemap.xml would need to aggregate across all of these systems into one index. Nobody owns that job, so each team generates their own sitemap from their own platform, and the robots.txt is the only place they come together.
The dead sitemaps support the theory: someone added them, then the system that generated them got deprecated, and there is nobody to do the clean up.
Does it hurt them? Not really. Google reads sitemap declarations from robots.txt just as reliably as from /sitemap.xml, and for a domain this authoritative, Google is finding pages through links anyway. Not the best practice though.
Let's move on the English-US hreflang sitemap, which alone contains 11,005 URLs. Most are from these directories:
| Section | URLs | Share |
|---|---|---|
/think/ | 5,303 | 48% |
/products/ | 1,748 | 16% |
/case-studies/ | 1,268 | 12% |
/new/ (press releases) | 1,175 | 11% |
/docs/ | 373 | 3% |
| Everything else (careers, training, history, solutions, consulting, quantum, etc.) | 1,138 | 10% |
Nearly half the indexed site is /think/.
And inside /think/, there are three distinct layers.
Layer 1: Hub landing pages (32 hubs)
Every hub follows the same template. It sits at /think/[topic], uses the same five-facet taxonomy, and serves as a front door for that subject. But each hub has its own content: its own subtopics, its own articles, its own depth.
| Category | Hub pages | Count |
|---|---|---|
| Technology topics | Analytics, Artificial Intelligence, Asset Management, Business Automation, Business Operations, Cloud, Compute and Servers, DevOps, IT Automation, IT Infrastructure, Middleware, Network, Quantum, Security, Storage, Sustainability | 16 |
| Industries | Automotive, Banking, Consumer Goods, Energy & Utilities, Government, Healthcare, Manufacturing, Retail, Telecommunications, Travel | 10 |
| Content types | Explainers, Insights, News, Newsletters, Reference Architectures, Tutorials | 6 |
The key architectural insight: the 16 technology hubs and 6 content type hubs use the full five-facet taxonomy with deep subtopics. /think/artificial-intelligence contains subtopics like AI agents, machine learning, and neural networks. /think/devops contains CI/CD, containers, and observability. Each one goes deep into its own subject with dozens of subtopic pages.
Each hub is a rich destination page. A reader arriving at /think/artificial-intelligence sees carousels of latest content, featured articles, learning sub-hubs (e.g. "AI agents", "Machine learning", "Prompt engineering"), embedded podcast episodes, newsletter signup forms, and guidebook callouts.
The 10 industry hubs are structurally simpler. Pages like /think/healthcare don't have the taxonomy filters. They're article feeds: a curated list of content tagged with that industry. They serve as entry points for readers who think in terms of their vertical rather than a technology, but they don't have the same depth as the technology hubs.
But generally, every hub uses the same five-facet taxonomy to let readers drill deeper:
| Facet | What it controls | Strategic purpose |
|---|---|---|
| Topics | Sub-topics unique to this hub (e.g. DevOps has CI/CD, Containers, Observability) | Lets readers drill into a specific angle without leaving the hub |
| Industries | Vertical cross-cuts (Healthcare, Financial services, Manufacturing, etc.) | Surfaces industry-relevant content from across the hub |
| Content Format | Article, Podcast, Video, Interactive | Readers self-select their preferred format |
| Content Type | Explainers, Insights, Interview, News, Tutorial, Keynote, Use case | Separates "what is X" from "how to do X" from "what happened this week in X" |
| Series | Recurring programs: Mixture of Experts, AI Academy, AI in Action, etc. | Creates subscription-worthy shows |
When you click a subtopic in the Topics filter (e.g. "CI/CD" inside the DevOps hub), you land on a dedicated subtopic page at /think/topics/ci-cd. That page covers different angles of CI/CD through articles, tutorials, podcasts, and videos. That's where the real depth lives.
Layer 2: How deep does a single hub go? (The AI hub dissected)
The best way to understand how IBM ranks #1 for "ai agent" is to look at exactly how deep the Artificial Intelligence hub goes.
The hub at /think/artificial-intelligence is the front door. It aggregates and surfaces all AI content through the taxonomy filters. The pages that actually rank are the individual topic pages underneath it: /think/topics/artificial-intelligence ranks #1 for "what is ai" and #4 for "ai" (241k traffic). /think/topics/ai-agents ranks #1 for "ai agent" (23k traffic).
Inside the AI hub, the Topics filter reveals 37 subtopics:
| Subtopic | Pages | What it covers |
|---|---|---|
| Machine learning | 195 | The deepest cluster in the hub |
| AI agents | 154 | The fastest-growing cluster |
| AI models | 136 | LLMs, foundation models, fine-tuning |
| Generative AI | 134 | Gen AI applications, limitations, trends |
| AI governance | 104 | Ethics, regulation, responsible AI |
| Enterprise AI | 63 | Business adoption, ROI, strategy |
| Prompt engineering | 33 | Prompt design, optimization |
| Chatbots | 20 | Conversational AI |
| + 29 more subtopics | ~60 | From "knowledge graphs" to "artificial superintelligence" |
37 subtopics. Nearly 800 pages just inside the AI hub. Each subtopic is its own cluster of content.
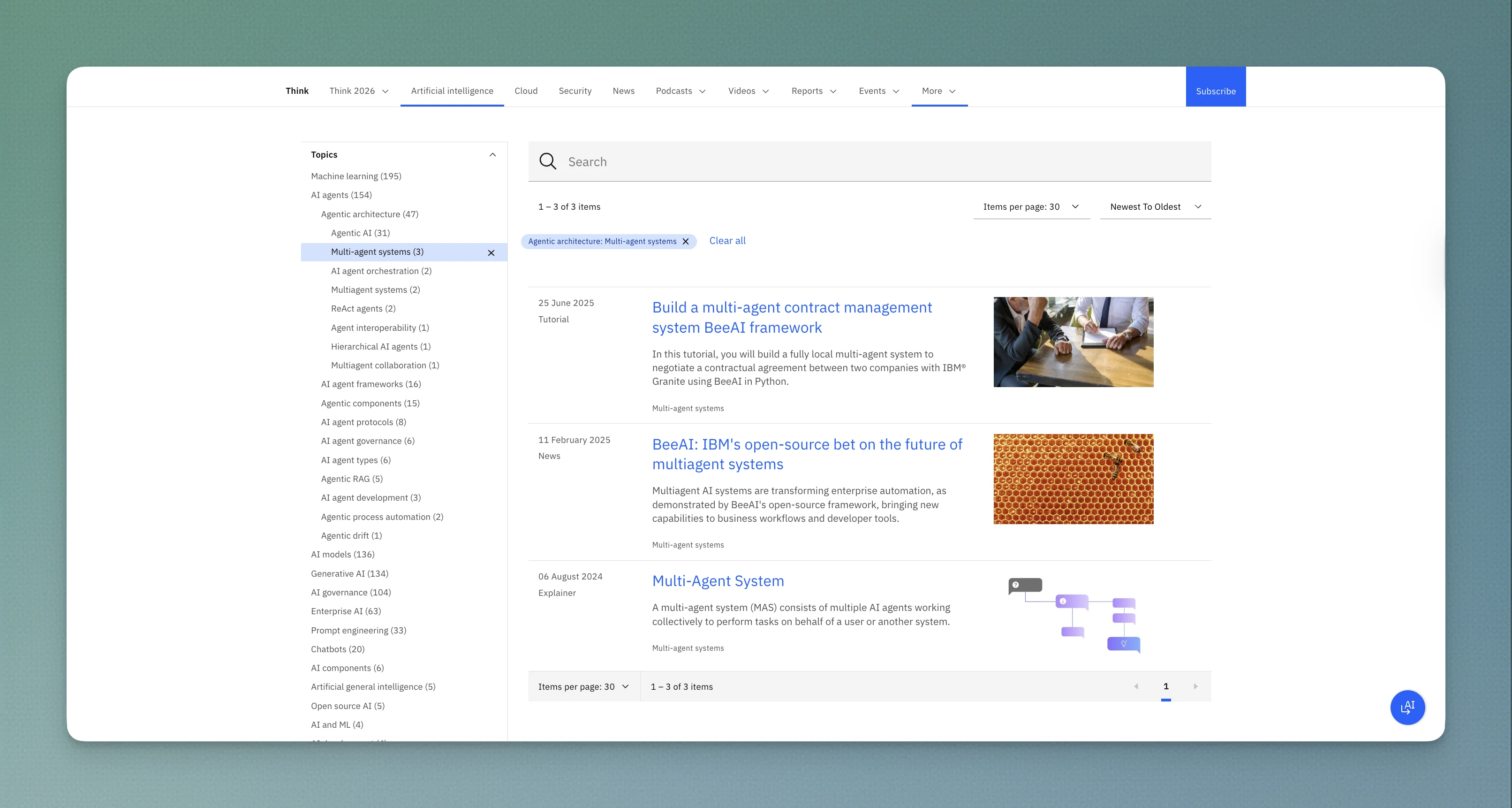
Click into "AI agents" (154 pages) and it breaks down further:
| Sub-subtopic | Pages |
|---|---|
| Agentic architecture | 47 |
| AI agent frameworks | 16 |
| Agentic components | 15 |
| AI agent protocols | 8 |
| AI agent governance | 6 |
| AI agent types | 6 |
| Agentic RAG | 5 |
| AI agent development | 3 |
| Agentic process automation | 2 |
| Agentic drift | 1 |
154 pages covering 10 distinct angles of "AI agents" alone. Each one is a sub-cluster with its own dedicated content.
Click into "Agentic architecture" (47 pages) and it breaks down again:
| Sub-sub-subtopic | Pages |
|---|---|
| Agentic AI | 31 |
| Multi-agent systems | 3 |
| AI agent orchestration | 2 |
| ReAct agents | 2 |
| Agent interoperability | 1 |
| Hierarchical AI agents | 1 |
| Multiagent collaboration | 1 |
From "artificial intelligence" → "AI agents" → "agentic architecture" → "multi-agent systems."
Four levels deep. And at the bottom of that tree, you find articles per leaf topic: an explainer, a tutorial, maybe a news piece covering the latest development.
Why this matters for ranking
When someone searches "ai agent," Google doesn't just match that query to one page.
It decomposes it into sub-queries: what is an ai agent, ai agent use cases, ai agent vs chatbot, how to build an ai agent, ai agent frameworks, agentic architecture, etc.
IBM has a dedicated page for nearly every sub-query. And all of those pages are interlinked within the same hub, reinforcing each other.
This is what "topical authority" looks like in practice. It's not a 5,000-word pillar page. It's 154 pages organized into a four-level taxonomy, each page answering one specific question, all connected back to the hub.
The content mix across all hubs
| Content type | URLs | Role |
|---|---|---|
Subtopic explainer pages (/think/topics/) | ~1,938 | The depth: one page per sub-query |
Blog articles (/think/insights/) | ~1,344 | Timely takes, opinion, analysis |
Author profiles (/think/author/) | ~966 | E-E-A-T signals: who wrote what |
News articles (/think/news/) | ~299 | Freshness signals on evergreen hubs |
Security research (/think/x-force/) | ~270 | Specialized threat intelligence |
Podcast episodes (/think/podcasts/) | ~231 | Audio format, embedded on topic pages |
Technical tutorials (/think/tutorials/) | ~96 | Hands-on code walkthroughs |
Video pages (/think/videos/) | ~70 | Lightboard explainers |
Reference architectures (/think/architectures/) | ~37 | Technical diagrams and patterns |
The ratio tells the story: for every ~1.4 subtopic explainer pages, there is 1 blog article. IBM isn't running a blog with topic pages on the side. They're running a topic encyclopedia with a blog, podcast, video, and tutorial layer on top.
There are also ~966 author profile pages, almost as many as blog articles. IBM is indexing individual author profiles as standalone SEO pages, almost certainly for E-E-A-T signals.
What the #1 ranking page actually looks like
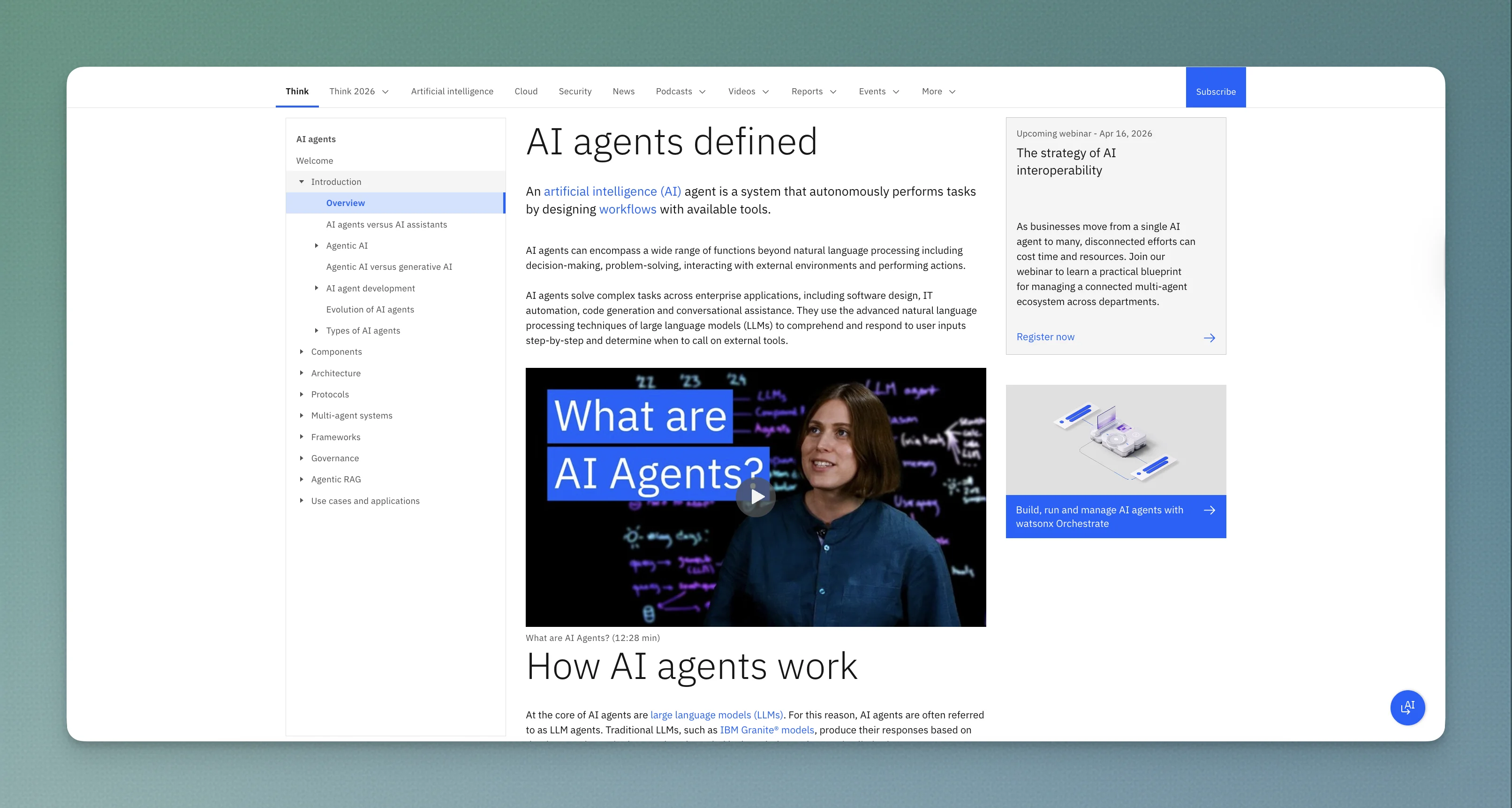
The page that ranks #1 for "ai agent" is /think/topics/ai-agents and here's the anatomy:
/think/topics/ai-agents
│
├── Introduction
├── Overview
├── AI agents vs AI assistants
│
├── Agentic AI
│ └── Agentic AI vs generative AI
│
├── AI agent development
│ ├── Evolution of AI agents
│ └── Types of AI agents
│ ├── Simple reflex agents (with diagram)
│ ├── Model-based reflex agents (with diagram)
│ ├── Goal-based agents (with diagram)
│ ├── Utility-based agents (with diagram)
│ └── Learning agents (with diagram)
│
├── Components
├── Architecture
├── Protocols
├── Multi-agent systems
├── Frameworks
├── Governance
├── Agentic RAG
│
└── Use cases and applications
On-page elements that make this page rank:
| Element | What it does | SEO/UX purpose |
|---|---|---|
| Sidebar table of contents | 18-section navigation | Generates jump links in Google SERPs, keeps readers oriented |
| Embedded lightboard video (12:28 min) | "What are AI Agents?" explainer | Time-on-page signal, video SERP eligibility, YouTube cross-link |
| 5 agent type diagrams | Simple reflex, model-based, goal-based, utility-based, learning agent | Custom illustrations with alt text, image search visibility |
| Mid-article newsletter signup | "The latest AI trends, brought to you by experts" | Converts reader to subscriber mid-engagement |
| Podcast embed | Techsplainers episode: "What are AI agents?" | Freshness signal, audio format for accessibility |
| Author profile | Anna Gutowska, AI Engineer, Developer Advocate at IBM | E-E-A-T: real person with verifiable credentials and job title |
| Internal links | Links to related /think/topics/ pages throughout the body | Spreads authority across the hub, keeps reader in the system |
The content itself is encyclopedic.
- The "Types of AI agents" section alone covers five agent types, each with a custom diagram, a definition, and a real-world example (thermostat, robot vacuum, navigation system, fuel-efficient routing, e-commerce recommendations).
- The "How AI agents work" section explains the three-stage process (goal initialization, reasoning with tools, learning and reflection) with a concrete scenario (planning a surfing trip in Greece).
It's a reference document designed to be bookmarked, returned to, and cited. And that's exactly what Google rewards: the page has likely accumulated returning-visitor signals for months, reinforcing its ranking position.
The contrast with typical B2B content: Most companies write a 2,000-word blog post titled "What Are AI Agents?" and hope it ranks. IBM wrote a 5,000+ word reference page with a video, five diagrams, a podcast embed, a newsletter signup, 18 navigable sections, and an author with "AI Engineer" in her title. Then they surrounded it with 153 other pages covering every angle of the same topic, all linked back to the hub.
Layer 3: The cross-linking logic
Here is how the layers connect. Every arrow is a real internal link or embed on IBM's site:
┌─────────────────────────────────────────────────────┐
│ /think/artificial-intelligence (hub landing page) │
│ /think/healthcare (same template, industry filter) │
│ /think/insights (same template, format filter) │
└──────────┬──────────────────────────────────────────┘
│ surfaces content from
┌────────┼────────────────────────┐
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│/think/topics/│ │/think/topics/│ │/think/topics/│
│ ai-agents │ │ machine- │ │ neural- │
│ │ │ learning │ │ networks │
└──┬───┬───┬───┘ └──────────────┘ └──────────────┘
│ │ │
│ │ └──── embeds ──────────┐
│ │ ▼
│ │ ┌──────────────────┐
│ └── links to ──▶ │/think/insights/ │
│ │ (blog articles) │
│ └──────────────────┘
│
├── embeds ────────▶ ┌──────────────────┐
│ │/think/podcasts/ │
│ │ (Friday episode) │
│ └──────────────────┘
│
├── embeds ────────▶ ┌──────────────────┐
│ │/think/videos/ │
│ │ (lightboard) │
│ └──────────────────┘
│
├── links to ──────▶ ┌──────────────────┐
│ │/think/tutorials/ │
│ │ (hands-on code) │
│ └───────┬──────────┘
│ │
│ ▼
│ ┌──────────────────┐
│ │ GitHub repo │
│ └──────────────────┘
│
└── attributed to ▶ ┌──────────────────┐
│/think/author/ │
│ (E-E-A-T signal) │
└──────────────────┘
The diagram shows the flow from one hub's perspective, but the critical insight is that ALL 32 hubs draw from the same pool of content pages. The DevOps hub and the Healthcare hub can both surface the same /think/topics/ci-cd page if it's tagged with both. One piece of content, multiple entry points.
Every page is a node in a web, not an item in a list. A reader entering at any point can navigate to any other point without leaving the system.
Now let's get into how the other assets in the system work.
1. Pillar pages paired with lightboard video
Every major topic on IBM's site has a written pillar page and a video pillar. The "What are AI Agents?" article at /think/topics/ai-agents embeds a video at the top. The video description links back to the article. Both exist as part of the same content unit, not sequenced (video after article, or article after video).
The YouTube channel (IBM Technology, 1.64M subscribers, ~1,600 videos) mirrors the /think/ hub structure.
The playlists map directly to the topic taxonomy:
| YouTube playlist | Videos | Avg. views per hour | Mirrors which hub |
|---|---|---|---|
| AI Agents Explained | 44 | 18 VPH | /think/topics/ai-agents |
| AI Models Explained | 40 | 107 VPH | /think/topics/ai-models |
| AI Fundamentals | 44 | 107 VPH | /think/artificial-intelligence |
| AI Security Explained | 15 | 6 VPH | /think/security |
| Cloud Security Explained | 32 | 2.5 VPH | /think/security + /think/cloud |
| DevOps Explained | 18 | 1 VPH | /think/devops |
| Kubernetes Essentials | 18 | 4 VPH | /think/devops subtopic |
| Quantum Computing Essentials | 10 | 3 VPH | /think/quantum |
| Data Explained | 11 | 16 VPH | /think/analytics |
| AI Academy | 24 | 3 VPH | Academy learning hub |
The AI Agents playlist alone has 44 videos and over 2.3 million total views. The top video ("What are AI Agents?") has 1.6M views and is the exact video embedded on the #1 ranking page.
The channel also hosts 4 podcast series as video podcasts. Mixture of:
- Experts (107 episodes)
- Security Intelligence (28 episodes)
- AI in Action (45 episodes)
- Smart Talks with IBM (20 episodes)
The pairing works in both directions: the article gets time-on-page and engagement from the embedded video, the video gets authority from being linked on a #1 ranking page.
And because the YouTube playlists mirror the hub structure, a viewer who watches one AI agents video gets recommended the other 43, keeping them inside IBM's content system even on YouTube.
This has been running for six years. Most competitors are still treating video as a secondary channel they will get to after the blog is fixed.
2. A newsletter system, not a single newsletter
IBM doesn't run one newsletter. They run seven, each targeting a different audience segment:
| Newsletter | Frequency | Audience | What it covers |
|---|---|---|---|
| Think | Twice weekly | Business leaders, marketers | AI-focused industry news, expert perspectives, trends in AI, security, sustainability |
| What's New at IBM | Bi-weekly | Existing customers, technical buyers | Product features, releases, roadmaps, videos, trainings |
| Future Forward | Regular | Innovation leaders, R&D | Emerging tech research, scientific developments |
| IdeaWatch | Monthly | C-suite, strategists | IBM Institute for Business Value research reports, thought leadership |
| Developer Digest | Regular | Developers | Technical content updates on developer tools and technologies |
| Redbooks | Regular | Technical practitioners | IBM Redbooks publications, technical guides |
| The DX Leaders | Regular | Japanese market | Business and technology content curated for the Japanese audience |
It's positioned as a publication, not a company mailer. A CTO might subscribe to Developer Digest and Future Forward. A CFO might get IdeaWatch. A product manager might read What's New at IBM.
The newsletters serve two purposes:
- Distribution for the website and podcasts. Every issue pulls readers back to IBM.com articles and links out to fresh podcast episodes. The Think newsletter is the primary distribution channel for new
/think/content. - A subscription-style audience asset. Enterprise sales cycles are long (often 12-24 months). A subscriber who joins Think at month zero has been reading IBM's POV for a year by the time they're ready to buy. Seven newsletters means seven touchpoints across different personas in the same buying committee.
3. News-cadence podcasts
IBM publishes podcasts covering last week's news in AI and cybersecurity on a Wednesday-topic, Thursday-record, Friday-ship cadence.
The podcasts are distributed across IBM.com in an unusual way: every relevant podcast episode is embedded on the evergreen article page for its topic. This means a reader landing on IBM's "what is an ai agent" pillar page (written perhaps six months ago) sees a podcast from two days ago sitting next to the article.
For Google, this creates a "news-cycle relevance" signal on pages that would otherwise look stale. For readers, it answers the "is this content still up to date?" question.
4. Technical tutorials from in-house engineers
IBM hires PhDs and developer advocates to produce hands-on tutorials. Not sponsored content. Not agency-produced explainers. Actual code walkthroughs written by engineers with domain credibility.
Here's a concrete example of how a tutorial connects to the hub:
/think/topics/ai-agents (the #1 ranking page)
│
├── Table of contents section: "Frameworks"
│ ├── LangChain
│ ├── LangGraph
│ ├── crewAI
│ ├── AutoGen
│ ├── BeeAI
│ └── ...6 more frameworks
│
└── LangChain page links to:
│
└── Tutorial: "LangChain tool calling using Granite-3.0-8B-Instructions
│
├── Step-by-step Python implementation:
│ ├── Set up watsonx.ai credentials
│ ├── Initialize Granite model
│ ├── Configure LangChain tools (YouTube, weather...)
│ ├── Create ReAct agent
│ └── Run multi-tool queries with full code output
│
├── Available as Jupyter notebook on watsonx.ai
├── Available on GitHub (ibmdotcom-tutorials repo)
│
└── Author: Anna Gutowska (same author as the AI agents explainer)
└── /think/author/anna-gutowska links to both pages
One piece of content, four surfaces: the hub, the tutorial page, the Jupyter notebook, and GitHub.
The tutorials had a distribution problem initially: they were expensive to produce (PhD-level labor, code, testing) and hard to get traffic to. The fix was packaging them inside the topic hubs alongside explainer content. Once a tutorial lived inside a hub with a top-of-funnel pillar page, Casey said distribution roughly tripled.
5. GitHub as a distribution endpoint
IBM's GitHub organization has 3,841 repositories and 7,900+ followers. The ibmdotcom-tutorials repository is the landing point for tutorial code from the /think/ content system.
The repo mirrors the hub structure:
| Directory | What it contains |
|---|---|
generative-ai/ | Gen AI tutorials (text classification, etc.) |
crew-ai-projects/ | crewAI multi-agent examples |
sql-agent-app/ | SQL agent application code |
ai-models/ | Model-specific tutorials |
machine-learning/ | ML tutorials (NLP, PyTorch) |
docs/ | Tutorial documentation including AI agent security |
Each tutorial on /think/tutorials/ links to the corresponding GitHub directory. Each GitHub README links back to the /think/ tutorial page. The code is also available as a Jupyter notebook inside watsonx.ai.
This creates a three-way loop: /think/topics/ explainer → /think/tutorials/ walkthrough → GitHub repo → back to related hub content.
A developer who finds IBM via a "what is RAG" query can move from explainer to working code without leaving the system. And every link between these surfaces strengthens the internal linking graph that Google uses to evaluate topical authority.
IBM's broader GitHub presence (3,841 repos, 20,000+ commits per month, 25+ years in open source) adds another layer of credibility. The ibmdotcom-tutorials repo is a small part of that, but it sits inside an organization that includes Plex (IBM's typeface, 11.3K stars), Sarama (Apache Kafka library, 12.5K stars), and mcp-context-forge (3.6K stars).
6. The hidden asset: research.ibm.com (84,736 URLs)

The topic clusters were generated via Topic Cluster Generator - try it, it's free
Research wasn't mentioned by Casey, but it is run by IBM Research. It may be the single most important structural advantage in IBM's entire SEO picture.
research.ibm.com has its own sitemap with 17 sub-sitemaps, and I crawled all of them:
| Section | URLs | What it is |
|---|---|---|
/publications/ | 82,869 | Individual research paper pages |
/people/ | 1,025 | Researcher profile pages |
/blog/ | 568 | Research blog posts |
/projects/ | 178 | Research project pages |
/topics/ | 69 | Topic landing pages |
| Everything else | ~27 | Labs, events, about |
82,869 publication pages. Each one is a citation magnet. Academic papers get linked from other papers, university sites, Wikipedia, government documents. Those are the most authoritative backlink sources on the internet, and they flow link equity into the ibm.com root domain because research.ibm.com is a subdomain sharing the same domain authority.
The research subdomain is 16x larger than the entire content engine by URL count, but almost all of it is thin publication metadata (title, abstract, authors, PDF link).
It is not competing for the same keywords Casey's team targets. It serves a completely different function: building the domain-level authority and E-E-A-T reputation that makes everything on /think/ rank as easily as it does.
Think of IBM's indexable web presence as three layers:
| Layer | Domain | URLs (EN) | Purpose |
|---|---|---|---|
| Content engine | ibm.com/think/ | ~5,300 | Organic traffic, audience, leads |
| Commercial site | ibm.com | ~5,700 | Products, case studies, solutions |
| Academic credibility | research.ibm.com | ~84,700 | Publications, backlink magnet, E-E-A-T |
This is the hidden moat. No startup can easily replicate 83,000 academic publications.
The SEO mechanics: why this structure wins with Google
The architecture above is not optimized for aesthetics. It is optimized for four specific mechanics that Google's current algorithm (and the LLM answer engines) reward disproportionately.
| Mechanic | What Google rewards | How the hub design exploits it | Observable evidence |
|---|---|---|---|
| Topical authority | Comprehensive coverage of a subject at the domain level | 1,000+ items per parent hub, 70+ pages per sub-hub (and growing) | #1 for "ai agent", #1 for "what is ai" |
| Query fan-out | Ability to answer all sub-queries a top-level search decomposes into | Dense hub guarantees at least one strong answer per sub-query | Hub pages rank for hundreds of long-tail variations |
| Returning-visitor signal | Pages that act as reference, not disposable content | Hub structure turns articles into a library you come back to | +50% returning visitor traffic after restructuring |
| AI visibility | Legible authority signals for LLM citation | Dense hubs read as authoritative sources to answer engines | Casey explicitly called the hubs "super useful from an AI visibility perspective" |
Topical authority through density
Google's algorithm increasingly evaluates a domain's comprehensiveness on a subject rather than scoring individual URLs in isolation. A sub-hub with 70+ interlinked pages on "AI agents" (Casey's number from late 2025, likely higher now) sends a different signal than a single 8,000-word pillar page on the same topic, even if both cover the same ground in total word count. And that sub-hub sits inside a parent hub with over a thousand items.
IBM's hubs are built to maximize this signal. Each hub has:
- A clear root pillar page that captures the generic head term
- 10–30 secondary pages targeting specific subtopics and modifiers
- 10–30 tertiary pages targeting long-tail and question-form queries
- Tutorial pages covering practical implementations
- Comparative pages targeting "X vs Y" queries
The density of interlinking within a hub tells Google that IBM is not merely aware of the topic. It is treating the topic as a domain of expertise.
And underneath all of this, the 83,000 research publications on research.ibm.com are quietly feeding domain-level authority back into the root. Every Nature paper, every IEEE citation, every Wikipedia reference that points to an IBM Research publication strengthens the same domain that hosts /think/topics/ai-agents. Casey's team is riding a wave of academic credibility they didn't have to build themselves.
Query fan-out exploitation
Modern Google does not simply match a query to a page. It decomposes a query into multiple sub-queries, runs each of them against its index, and selects pages that score well across the full decomposition. This is referred to in the industry as query fan-out.
A site with comprehensive hub coverage benefits from this disproportionately, because the hub already contains an answer for nearly every sub-query a top-level search might fan out into. A site with scattered standalone articles has to get lucky across multiple independent searches.
IBM's hubs are effectively pre-optimized for query fan-out by virtue of their density. Any query that Google decomposes into 3–8 sub-queries is likely to find at least one strong answer somewhere in the hub, which lifts the whole hub in the rankings for the original query.
Returning visitor signals
When Casey's team restructured the blog into hubs, returning visitor traffic to hub pages increased by 50%.
Google interprets returning visitors as a sign that a page is a reference, not a disposable piece of content. Reference pages rank better and retain their rankings longer than transactional pages. The hub architecture turned IBM's content from a blog (where people read one article and leave) into a reference library (where people return multiple times).
AI visibility
The same density that wins traditional SERPs wins AI Overviews, Perplexity citations, and LLM-generated answers. Generative search engines are looking for authoritative sources to cite, and a sub-hub with 70+ pages inside a parent hub of 1,000+ items is a more legible authority signal than a single post of any length.
IBM's team did not build for AI visibility explicitly. They built for topical authority over the years. AI visibility was a downstream benefit of the same structural decisions. And when an LLM is deciding which source to cite on "what is an AI agent," the fact that the same root domain also hosts 83,000 peer-reviewed research papers is not a small signal. LLMs are trained on those papers. IBM is most likely in the training data.
The multi-channel flywheel
Observing the architecture in isolation misses the most important part of the system: the interlinks between the six assets above.
None of IBM's six assets stands alone. Each one is designed to accelerate the others, and the whole system compounds in ways that linear channel thinking does not capture.
Casey described the effect with a single statistic: "Every investment in search is now 40% more valuable because of the investments in the newsletter."
The newsletter does not merely add a channel. It makes the search channel more valuable by converting visitors into subscribers, which lifts returning-visitor metrics, which lifts search rankings, which drives more search visitors, which drives more newsletter signups.
A simplified map of the reinforcement:
┌──────────────┐
┌──────▶│ Newsletter │──────┐
│ │ (7 lists) │ │
│ └──────────────┘ │
│ surfaces │
│ episodes │
│ ▼ │
┌─────────┴──┐ ┌──────────────┐ │
│ SEO traffic │◀──│ Podcast │ │
│ /think/ │ │ (Fri 5am) │ │
│ hub pages │ └──────────────┘ │
└──┬──┬───┬───┘ │
│ │ │ │
│ │ │ embeds video │
│ │ └───────────────▶┌───────────┐│
│ │ │ YouTube ││
│ │ ◀─ engagement ────│ 1.64M ││
│ │ │ subs ││
│ │ └───────────┘│
│ │ │
│ │ surfaces tutorials (3x lift) │
│ └───────────────────▶┌───────────┐│
│ │ Tutorials ├┘
│ │ (in-house │ ladders up to
│ │ PhDs) │ newsletter subs
│ └─────┬─────┘
│ │
│ │ links to code
│ ▼
│ ┌───────────┐
│ │ GitHub │
│ │ 3,841 │
│ ◀─ READMEs link ───│ repos │
│ back to /think/ └───────────┘
│
│ ╔════════════════════════════════════╗
└──║ research.ibm.com (84,736 URLs) ║
║ Feeds domain authority into ║
║ everything above. The hidden moat. ║
╚════════════════════════════════════╝
Every arrow increases the value of the source and the destination. Remove any single node, and the system still functions. Remove all of them simultaneously, and nothing works.
The operational model
An architecture is not a program. IBM ships at this velocity because the team operates under four rules that most content teams never adopt.
Rule 1: Fully contained programs only
Casey's team refuses to rely on ad-hoc cooperation from other teams. His observation: when an organic content program asks an unrelated team to take on a task "as part of their existing scope," the failure rate is approximately 100%.
Either the content team owns the headcount directly, or it negotiates a dedicated and specific percentage of another team's bandwidth up front.
That's how they ship via pre-negotiated resource contracts inside a 300,000-person company.
Rule 2: Cadence is a policy, not a negotiation
The Wednesday-topic/Thursday-record/Friday-ship podcast cadence is a fixed feature of the system, not a variable that gets re-debated for each episode. Legal gets a 1-hour review window for genuinely sensitive topics. Everything else ships under a standing disclaimer.
The review bottleneck is the single biggest cadence killer at large companies. IBM solved it by negotiating the approval framework once, up front, rather than fighting it per-piece.
Rule 3: No content strategists, only writers
Casey's team has no strategy layer. Everyone on the team writes. The implicit logic: strategy without shipping is worse than shipping without strategy, and a layer of people who only plan creates friction without producing output.
This rule is extreme and does not scale down cleanly. Smaller teams may need a strategic function because they cannot afford the trial-and-error that IBM's scale permits. But the principle is directionally correct: output volume is the leading indicator of content program health.
Rule 4: Internal comms
The least visible but possibly most important operational element is how the program is marketed internally at IBM. The team treats internal comms as a formal workstream, not an afterthought.
Specific tactics include:
- Internal blog posts on the company Slack
- Framing strategic proposals with single-line arguments rather than multi-slide decks (the 80%-of-IBM.com-deletion proposal was pitched as: "navigation and structure on the website is the number one client experience problem in the company")
- Collecting external recognition (Semrush reports, industry roundups) as validation for internal stakeholders who are not SEO experts
- Celebrating authoritative citations (Wikipedia links, government document references) in a dedicated Slack channel to build team morale
None of this is growth hacking. It is politics inside a large organization, and it is the reason the program has survived six years of executive rotation and budget cycles.
The durability thesis
The prevailing conversation in B2B content right now is about disruption. AI Overviews are eating click-through rates. LLM chatbots are displacing traditional search behavior. Half the industry is debating whether organic content is still a viable channel at all.
IBM is not in that conversation. Not because they are ignoring it, but because their system was built to survive it.
When any single node in IBM's architecture gets disrupted, the other nodes catch the weight. If Google Search starts sending 30% less traffic, the newsletter still ships. The podcast still drops on Friday. The tutorials still get used. The video embeds still make the article pages look alive. The GitHub community still grows. And underneath it all, 83,000 research publications keep quietly attracting the most authoritative backlinks on the internet, reinforcing everything above.
This is the actual meaning of Casey's "growth system" framing. The point of multi-channel content is not broader coverage. It is durability. A system with six reinforcing nodes cannot be killed by the disruption of any single channel. A single-channel program can.
The teams panicking about AI Overviews right now are panicking because they built a channel. The teams that will outlast the disruption are the teams that built a system.
Want to see the topical density of your own site? The free topic cluster generator takes a sitemap and returns a treemap of your actual clusters, including where you are diluted and where you have hub-level density. It is the fastest way to audit whether your structure looks more like IBM's architecture or more like a scattered feed.
